
【運営】って何?
みなさま、こんにちわ 株式会社Aiming 第二事業部 TeamCARAVAN所属 運営マネージャーの赤岩です。 みなさんは、【運営】ってどんな仕事をしているのか、ご[...]
勉強
こんにちは
株式会社Aiming 第二事業部 TeamCARAVAN所属 運営マネージャーの赤岩<アカイワ>です。
今回は、「Google Cloud BigQuery」について書いておこうと思います!
Aimingではデータ分析やゲームログを使った調査に【Google Cloud BigQuery】を使用しています。
これはGoogleさんが提供しているサービスになります。
Aimingで開発/運用しているタイトルの大半はこのサービスを利用しており、各タイトルのKPIを横断的に見れるAiming独自のWEBツールにもこの【Google Cloud BigQuery】を活用しています。
【Google Cloud BigQuery】に関してはAimingの開発者ブログにて第一事業部の中根さんが記事を書いていますので、よければコチラの記事も御覧ください。
新規のお客様には、最初の 90 日間に Google Cloud で使用できる無料クレジット $300 分を差し上げます。すべてのお客様は、10 GB のストレージと 1 か月あたり最大 1 TB のクエリを無料で利用できます。
Google cloudから引用
ゲームサーバーから送られてきたログを蓄積し、そのログを使用して検索/集計等を行うことができるWEBツールになっています。
GoogleさんのWEBツールなので、アカウントとネット環境さえあればどこでも使用できるのがメリット。
検索するのに必要な「SQL」も非エンジニアの方には難しく感じられると思いますが、初歩的なことなら結構簡単に行うことができるようになります。
先程から何度か触れていますが、Aimingでの使用用途は以下になります
「イベントの参加率が良かった」、「ここでやめるユーザー様が多い」、「このガチャはよく利用された」などデータを集計してゲームをより良いものするための指標を作るための情報を集めるのがデータ分析になります。
巷で噂の「KPI」ってやつですね。
実際の KPI は、その組織の特性や戦略によって異なる。組織の目標達成度合いを測る補助となるもので、特に成果を定量化しづらい知識ベースのプロセスに関するものが多い。
wiki引用
もちろん数字だけではなく、自分たちもプレイして感じたこともゲームに反映させていきますが、それの良し悪しを決める参考にKPIを活用しています。
主にお問い合わせなどの事実確認で使用します。
分析とは異なり、集計関数などはほぼ使用しないので、SQLの初心者でもすぐ見ることができます。
ゲームデータベース上でも確認はできますが、ログを見ることで時系列などを把握できたりすることができます。
それでは早速どうやって使っているか簡単に紹介していきたいと思います。
それでは試しにSQLを書いてみようと思います!
今回はサンプルデータを用意してきたのでそれを使っていこうと思います。
まずはお好きなブラウザを開いて~~
という茶番は置いといてGoogleさんのツールなので、「Google Chrome」で「Google Cloud BigQuery」を開きます。
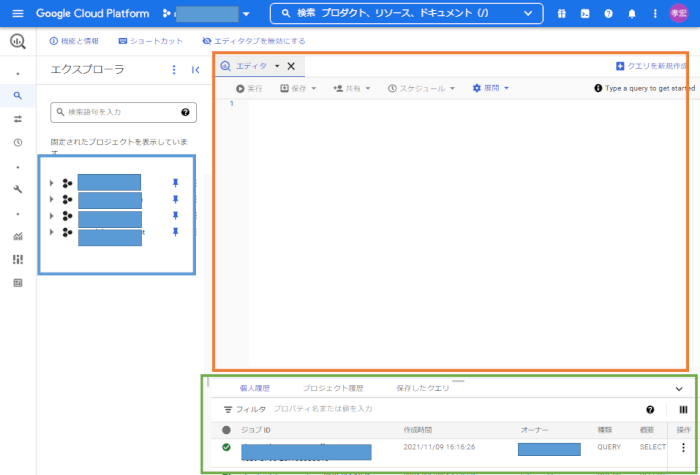
ここで使うSQLは「Standard SQL」という言語になります。
一応設定を変更することで「Legacy SQL」という言語でも使用可能です。
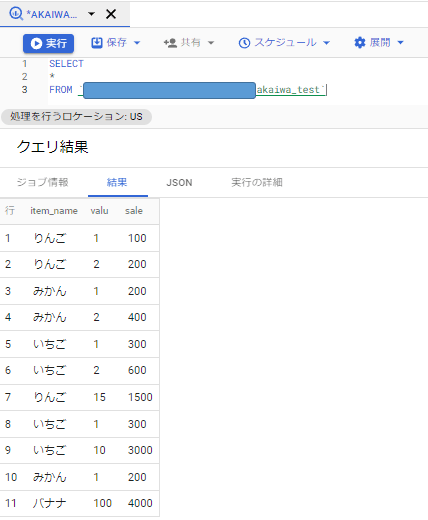
実際にサンプルデータを呼び出してみました。
基礎的な部分になりますが、データを呼び出すときは次の構文を使用します。
SELECT * FROM
「SELECT」はデータを呼び出すという指示になります。
続く「*」は「全データ」を指します。
そして「FROM」は呼び出すデータが格納されている場所を指定します。
つまり「SELECT * FROM」で「指定した場所に格納されているすべてのデータを表示する」と言う指示になります。
今回全データを持ってきましたが、「*」の部分を「item_name」や「sale」を指定することで、それらに属するデータだけを持ってくることも可能です。
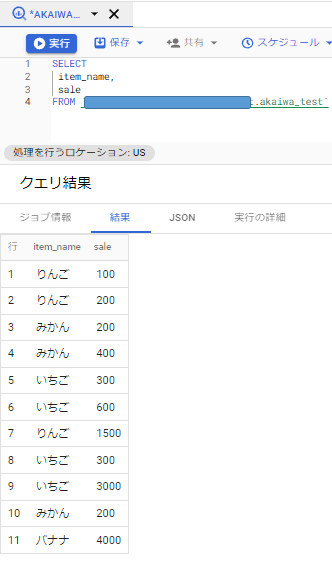
では、データを呼び出す事ができたので、これらを並び替え/抽出/計算してみようと思います。
それではまずは「並び替え」をして行きましょう。
並び替えはとっても簡単。
使う構文は「ORDER BY」です。
それではサンプルデータ内の「item_name」を使い昇順にしたいと思います。
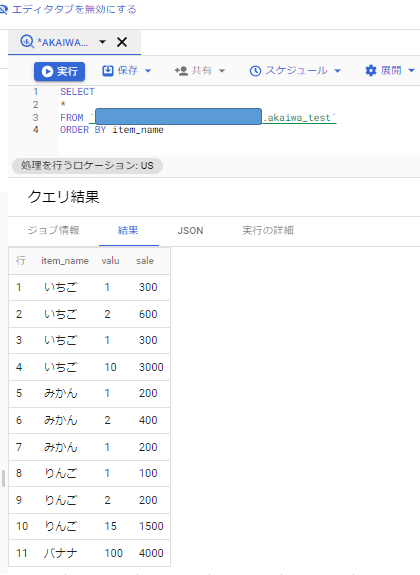
はい、並び替えが完了しました。
構文の最後に「ORDER BY」と基準を指定する形になります。
降順にしたい場合は、「ORDER BY item_name desc」と書けばOKです。
また、この並び替えは基準を複数指定することが可能です。
例えば「item_name」を昇順にならべ、その中で「valu」を降順で表示したい場合は次のように構文を書きます。
ORDER BY item_name,valu desc
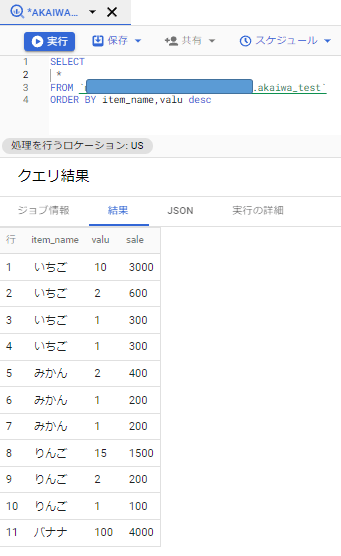
「,」を使うことで複数の対象が選択できるようになります。
並び替えをするとデータはかなり見やすくなるので覚えておきましょう!
では、続きまして「抽出」してみたいと思います。
今回は「みかん」だけのデータを抽出していきます。
使う構文は「WHERE」です。
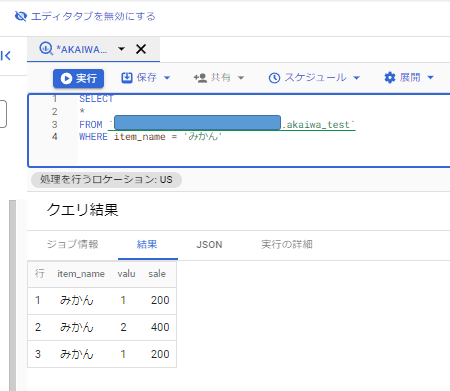
はい、できました!
「FROM」のあとに「WHERE item_name = ‘みかん’」と構文を追加した形です。
「WHERE」は「この条件に該当する」という意味だと思っていただければと思います。
なので、例文の形だと「item_nameがみかんのデータを抽出しなさい」という指示になります。
今回は「みかん」という条件にしましたが、条件を複数指定したい場合があると思います。
その時は「WHERE」と「AND」を使用します。
「=」は完全一位するものを対象としますが、「一部分だけ該当する」「該当しないデータのみ」「〇〇以上/以下」みたいな指定が可能です。
よく使うものを簡単にまとめてみました!
| 記述 | 意味 |
|---|---|
| = | 完全一致 |
| 以上 | >= |
| 以下 | <= |
| より上 | > |
| より下 | < |
| 部分一致 | LIKE %% |
これらを使うとより複雑なデータの抽出ができます。
例えばitem_nameが「りんご」でsaleの値が200以上のものだけ抽出したい場合は、次のような構文になります。
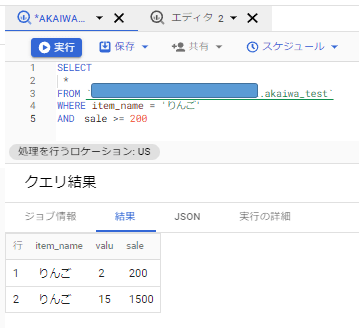
それでは次に「集計」をしてみたいと思います。
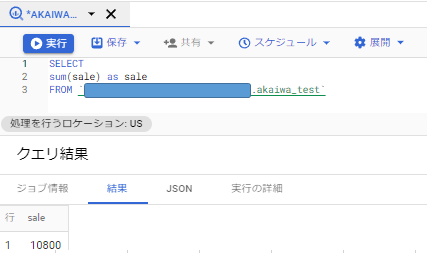
はい、できました!
「SELECT * FROM」の「*」の部分に「SUM() as 〇〇」入れる形です。
「SUM」自体は関数とかでよく見るやつと同じで「足し算」を意味しており、この構文で「このテーブルにある数字の合計を出せ」と言う指示になります。
「as 〇〇」の部分は集計後の値の名称を指定しており、今回は「sale」としていますが、違う名称に変更することも可能です。
SUMと同じルールで構文を変更すれば平均などの計算も可能です。
では、各item_name毎に足し算をしてみましょう!
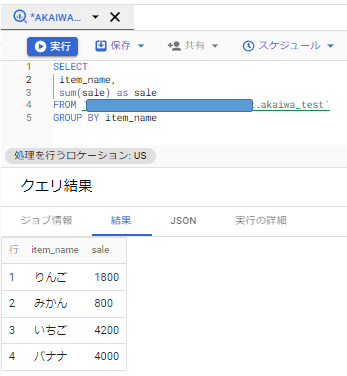
ポイントは「検索」との併用になります。
「item_name」を定義することで、そこに属するデータ毎に計算を行ってくれます。
この時使うのが「GROUP BY」という構文です。
これはデータをまとめるという指示になっており、何を基準でまとめるかを定義します。
ほんとに基礎中の基礎ですが、ここまでできればSQL初心者卒業です。
おめでとうございます。
他にも色々お伝えしたい検索/集計方法があるのですが今回はここまで
次回の講義をお楽しみに!
次回「UNION/JOIN」
いかがでしたでしょうか?
SQL講座は定期的にやっていければと思います。
【Google Cloud BigQuery】は結構な頻度でバージョンがアップデートされており、できることが増えているツールです。
可視化しやすい機能だったり、Googleスプレットシートとの連携などSQL以外でも【Google Cloud BigQuery】について触れていければと思っています。
今チーム内では分析に重点を置いたスタッフを育成するための座組を検討中です。
アカイワ含めTeamCARAVAN所属の非エンジニアでデータ分析しているスタッフは、独学で学んでいるスタッフが多いので、こういうSQLや分析といった業務経験をお持ちの方、大大大大募集中です。
もし、気になりましたら弊社への応募お待ちしております!
応募フォームはこちらからどうぞ!



